


Inference Operating System
for Token Factories
Transform heterogeneous AI hardware infrastructure of any scale into a governed,
production-grade token factory
Built for rapid adoption of new AI technologies into production while maximizing XPU active time and ROI

Runtime
Intelligence
Optimal Execution for
Every Request

Open, Heterogeneous
Architecture
Hardware-Agnostic and
Future-Ready

Production-Grade
Token Factory
Faster, Observable, and
Reliable Inference at Scale

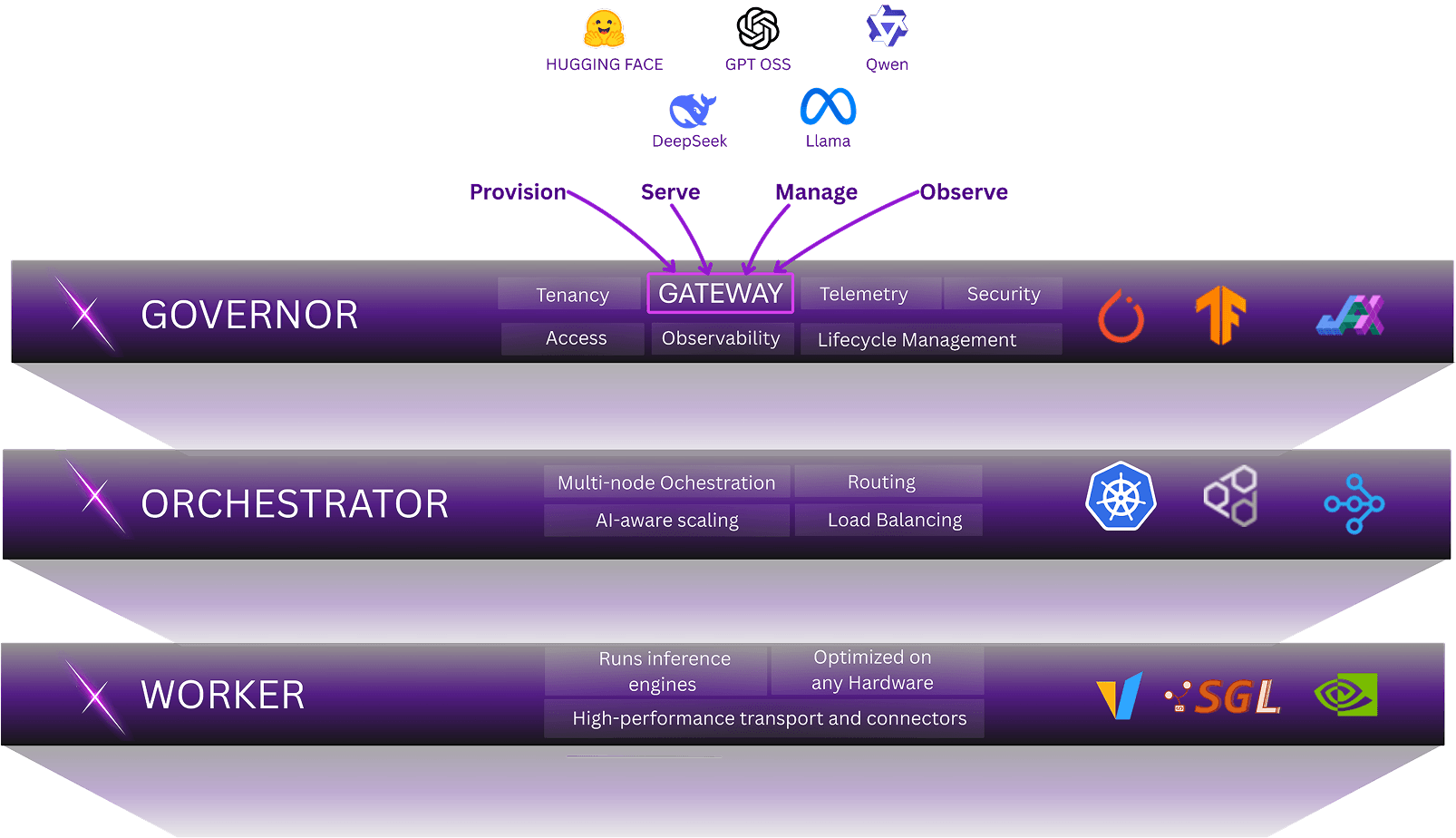
NR-Nexus: A Modular Approach for Highly Efficient Deployment
Worker optimizes node-level execution, Orchestrator scales nodes into optimized cluster-level distributed execution, and Governor manages all inference requests in a rule-based, secured, and observable manner.
If inference feels brittle,
it’s not your hardware.
It’s the stack.
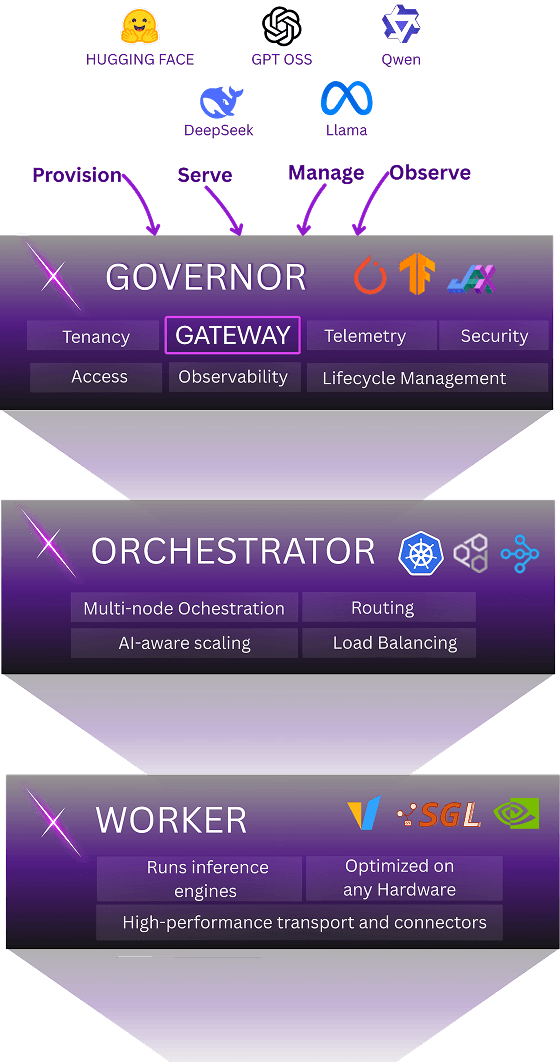
Inference at scale demands a unified system
Get Started





Performance
- Prefill/Decode disaggregation for LLMs
- Encode/Prefill/Decode for multimodal models
- Dynamic parallelism across pipeline, tensor, data, context, and experts

Memory and Cache
- KV cache sharing across instances
- Prefix caching to reduce repeat compute
- LMCache integration, embedding, and custom KV connectors
The levers that determine inference latency, tokens per second, and cost per token
NeoСlouds
Manage your transition from IaaS to PaaS and SaaS offerings
Extend your marketplace with Token Factory OS for enterprise customers
Enterprise
Transition from consuming high-cost proprietary models to owning your private token factory with open source models
Focus on AI adoption across your lines of business while relying on a production-grade, lifecycle-governed token factory ready for your choice of hardware, models, deployment KPIs, and full end-to-end control and visibility
Semiconductors
Couple your XPU stack and rack-scale offering with a complete token factory stack optimized to accelerate silicon monetization
Deliver the highest XPU active time to your customers beyond a single XPU, server node, or rack across any model size and mixture of distributed AI pipelines

Built for Production: Inference at Enterprise Scale

Take control of your inference economics
Evaluate NR-NEXUS in your cluster
Multi-node and multi-rack ready
Deploy on-prem or in the cloud