
What is theNeuReality
Solution?

It’s time to reimagine your AI infrastructure in the new AI era.
NR1®AI Inference Solutions are purpose-built to work with any AI model and any AI accelerator to drive AI data workloads at scale – and powered by the revolutionary NR1® Chip which replaces traditional CPU and NIC architecture to drives a new standard in inferencing price/performance.
The 7nm NR1 Chip is the first AI-CPU built to complement any GPU or AI Accelerator – unleashing their full potential by super boosting utilization from <50% today with traditional CPU and NIC architecture to nearly 100% with NeuReality. The result? Breakthrough improvements in cost, energy and space efficiency and 50-90% performance gains, up to 15x greater energy efficient, and 6.5x more AI token output versus yesterday’s CPU-reliant inference systems
Together with full-stack software, APIs and a generative and agentic AI-ready NR1 Inference Appliance, NeuReality makes AI easy to access, afford and adopt with redefined price/performance. Compare our Appliance housed with the NR1 Chip and any GPU – and you’ll see the difference.
NeuReality’s vision is to democratize AI for all business by making AI infrastructure accessible and ubiquitous.
 From Silicon to Software
From Silicon to Software



Software/APIs
Open ecosystem of upper-level AI tools for simplified inference deployment

Architecture
Purpose-built and optimized for AI inference orchestration

Silicon/Hardware
Migrates simple but critical data-path functions from software to hardware layer.
NeuReality Hardware


NR1® Chip
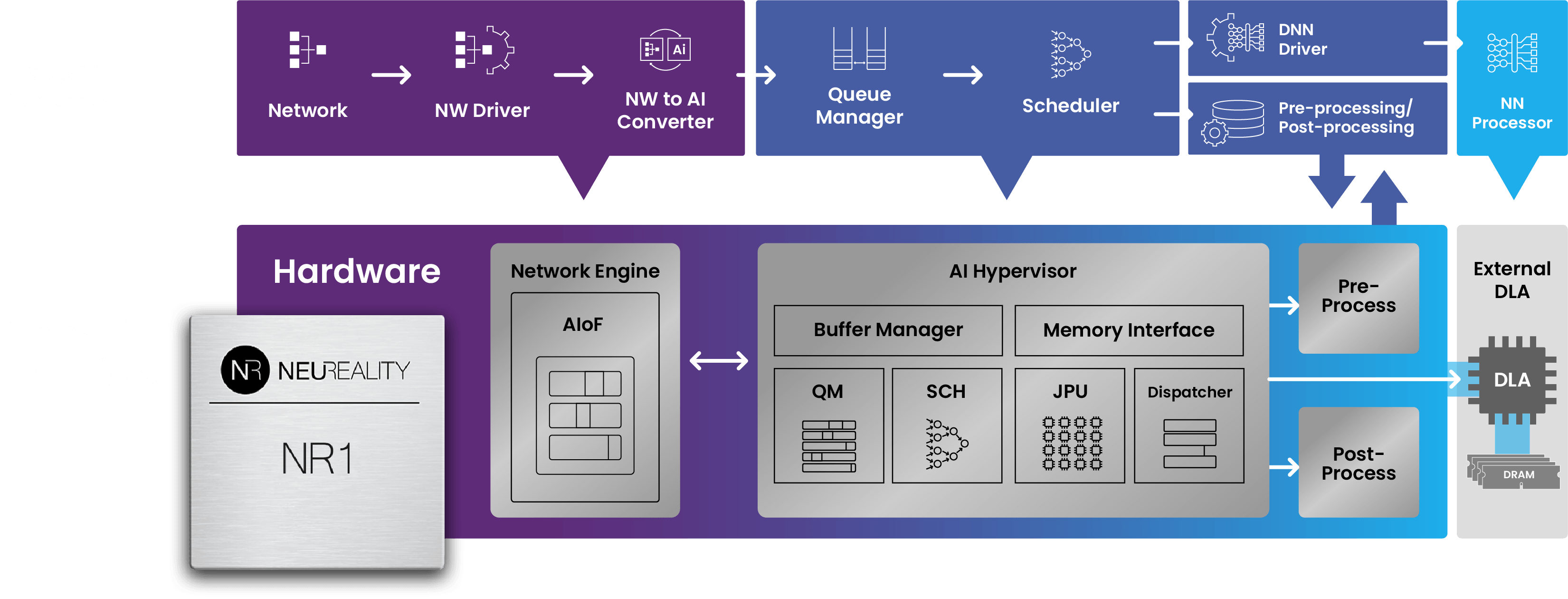
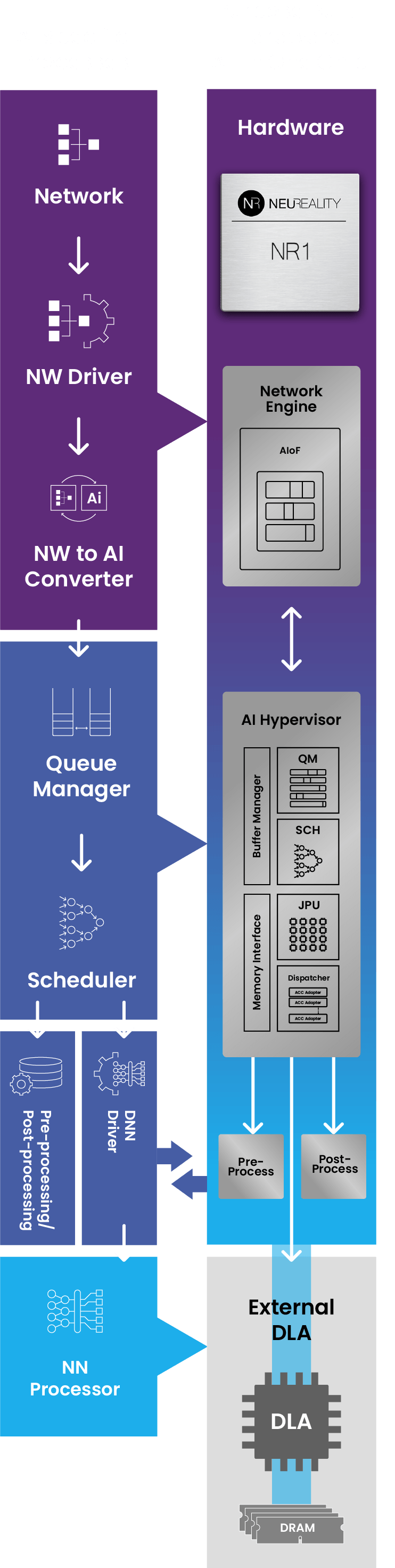
The NR1 Chip connects directly to the network and comes with a built-in neural network engine.
NR1 was designed to streamline AI workflows, featuring specialized processing units, integrated network functions, and virtualization capabilities. It excels in AI Inference tasks, providing optimal compute power for handling a wide range of AI queries and tasks for single and multi-modalities.

NR1® Module
The NR1 Module is a full-height, double-wide PCIe card containing one NR1 Chip that connects to any AI Accelerator – to significantly optimize its utilization rate.

NR1® Appliance
The ready-to-go, easy-to-use NR1 Appliance delivers redefined price/performance and built-in software and APIs. Inside, it houses several NR1 Modules, each equipped with an NR1 Chip, integrated with the AI accelerator of your choice – typically in 1:1, 1:2, or 1:4 configurations for high server density.
Our first cloud computing and financial services customers are currently running NR1 Appliances on site – demonstrating redefined price/performance with up to 6x better total cost per AI mega token versus traditional CPU/GPU set ups.
NeuReality® Software & Services
Develop, deploy, and manage AI inference
NeuReality is the only open, agnostic AI inference company that partners with AI software companies to improve overall system efficiency.
We bridge the gap between the infrastructure where AI inference runs and the MLOps ecosystem.
Our suite of software tools make it easy to develop, deploy, and manage AI inference.
Watch the video to learn more about our software.

Our Software Stack:

Works with any trained AI model in any development environment

Includes provisioning, deployment and manage tools that offload the complete AI pipeline

Connects AI workflows easily to any environment
Any data scientist, software engineer, or DevOps engineer can run any model faster and easier with less headache, overhead, and cost.
NeuReality APIs
Our SDK includes three APIs that cover the complete life cycle of an AI inference deployment:
| Toolchain API | Provisioning API | Inference API |
| For developing inference solutions from any AI workflow (Generative AI, Agentic AI, RAG, Computer Vision, Natural Language Processing, Automated Speech Recognition) | For deploying and managing AI workflows | For running AI-as-a-service at scale |
NeuReality Architecture
We deliver a new architecture design to exploit the power of today’s AI accelerators.
We accomplish this through the world’s first true AI-CPU called the NR1® Chip.
This architecture enables inference through hardware with our AI-over-Fabric® technology, AI-Hypervisor® hardware IP, and AI-pipeline offload.
This illustration shows all of the functionality that is contained within the NAPU:
CPUs: Never Meant for Efficient AI Inference
Traditional, generic, multi-purpose CPUs perform all their tasks in software, increasing performance bottlenecks and delays (high latency). They were never designed for the computational or network demands of AI Inference at scale.
Our purpose-built NR1 Chip was designed specifically for the demands of high-volume, high-variety AI pipelines, performing those same tasks in hardware versus software. The NR1 subsumes CPU/NIC into one with 6x the processing power. It’s the ideal complement to GPUs for near 100% utilization rates. As a result, you can get more from the GPUs you buy, rather than buying more than you need.
The following table compares these two approaches:
| AI Inference with NR1 (AI-CPU) | AI Inference with CPU | |
| Architecture Approach | Purpose-built for Inference workflows | Generic, multi-purpose chip |
| AI Pipeline Processing | Linear | “Star” model |
| Instruction Processing | Hardware based | Software based |
| Management | AI Process natively managed by cloud orchestration tools | AI process not managed, only CPU managed |
| Pre/Post Processing | Performed in Hardware | Performed in software by CPU |
| System View | Single chip host | Partitioned (CPU, NIC, PCI switch) |
| Scalability | Linear scalability | Diminishing returns |
| Density | High | Low |
| Total Cost of Ownership | Low | High |
| Latency | Low | High, due to over partitioning and bottlenecking |
